Find Best Neighborhood to Fight Pandemic in NYC - Results
Mar 30, 2020 · 3 Min Read · 2 Likes · 0 Comment
Disclaimer: this article has been generated as part of IBM Data Science Professional Certificate course’s final submission.
This report consists of three parts: business problem and data preparation, methodology, visualization and results. In this part, we are going visualize the data, discuss about the results and draw a conclusion.
Visualize with folium
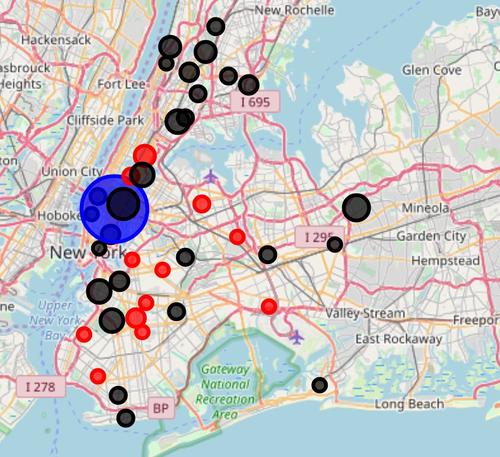
Now, we are going to use folium to visualize the distribution. The first map illustrates the clusters where the radius of the Circle marker is proportional to hospital beds per hundred people.
The second map illustrates the clusters where the radius of the Circle marker is proportional to icu beds per hundred people.
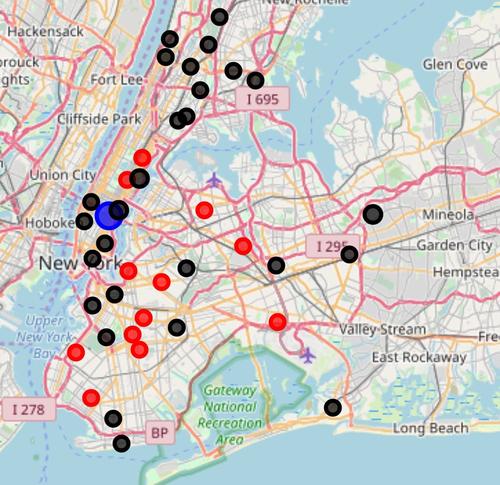
We can see that one of the clusters (blue circle) consists in one borough - Manhattan.
Use scatter plot
Let’s look at the scatter plots of our data and define our clusters with colors. The grey circle marker is representing the centroid of each cluster. Don’t forget that our data is normalized, so the axes do not deliver real values.
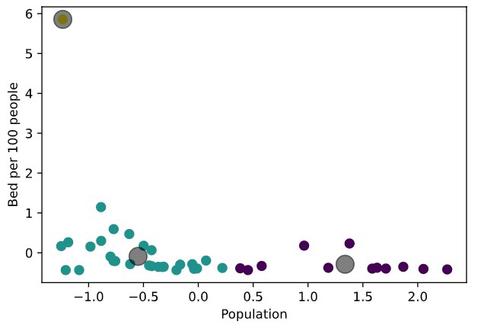
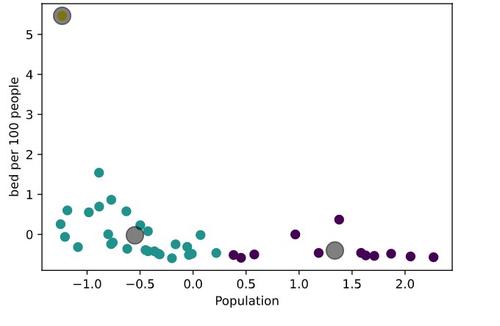
We can observe the obvious outlier here. This neighborhood has a high number of beds per people ratio. From maps above we can easily say that it is Murray Hill.
Results and discussion
During the analysis, three clusters were defined. One cluster(cluster 2), that consists of only one area, has been defined as the outsider, due to the high number of hospital beds, which means it is better equipped to handle this pandemic. Two other groups were clustered according to bed per hundred people and icu bed per hundred people. It is obvious that the cluster with the lowest beds per person is the place where we should concentrate on providing beds and other equipment(Cluster 0). We also should look into conditions in Queens Village and Williamsburg as they have very low beds per hundred people. Furthermore, in hundred other neighborhoods, there is no hospital data. Hence, people living there are at high risk of not being treated during pandemic.
What could be done better
Foursquare doesn’t represent the full picture, since many hospitals are not on the list. For that reason, other maps could be utilized such as Google map or OpenStreet map.
NYS Health Profile website might lacks the latest information regarding hospital information. It could lack information regarding new hospitals. Also, hospital ids were extracted manually from NYS, which could have missing hospitals. We also dropped neighborhoods which did not have any hospital data matching in NYS Health Profile website. For this project, we are only using data from 74 hospitals in NYC.
We are using fuzzy-wuzzy to match hospital data from Foursquare and NYS Health Profile. It is not a correct measure because we are matching the names nearest possible, it could be wrong in real life scenario.
We are also only considering hospital data. We did not consider other medical facilities like nursing home or health clinic.
We used population data from 2010(as per Wikipedia pages), which are not accurate currently. We should have used the latest population data.
Finally, to battle COVID-19, we should have had patient data for the neighborhood. Unfortunately, we could not find it like this(for example, get patient per latitude longitude) from any source, hence could not incorporate it.
Conclusion
To conclude, the basic data analysis was performed to identify the most well equipped hospital in the NYC neighborhoods. During the analysis, several important statistical features of the boroughs/neighborhoods were explored and visualized. Furthermore, clustering helped to highlight the group of optimal areas. Finally, Manhattan-Murray Hill was chosen as the most well equipped(as per hospital bed count and icu bed count) area to battle pandemic.
Last updated: Jul 03, 2026

