Beginner's Guide on Web Scraping using Python
Nov 12, 2020 · 7 Min Read · 18 Likes · 0 Comment
When it comes to web scraping, you have to keep in mind that it is not the coding skill rather cunning observations will get you results. Sometimes the data you get comes in a straight forward way, other times the website does not want you to crawl itself. Either way you will get the data, but it takes time depending on how many puzzles do you have to solve before getting it. Here are some tips to resolve these puzzles and code snippets to give you some heads up.
BeautifulSoup and requests are your friend
requests is the best library in python for making http requests. You can get the html data as a response from any website. Then you can purse the html data using Beautiful Soap(aka BS4). Here is an example to get all the links from Wikipedia front page:
import requests
from bs4 import BeautifulSoup
response = requests.get("https://wikipedia.com")
soap = BeautifulSoup(response.content, 'html.parser')
for a in soap.find_all('a'):
print(a['href'])
Majority of websites can be scrapped by these two libraries. A web scrapers best friends 😄.
Avoid crawling if there is an API
As said above, scraping data from the majority of websites is simple but we are not talking about Facebook or Twitter here because these websites don’t allow scraping or it may be illegal. Instead, you should look for APIs to get the needed data. So before scraping, try looking for API documentation of any site, and if it is an RESTful API, then use requests library to get the data. You can use other libraries such as BS for SOAP API etc.
There is another reason to avoid scraping, that is the website changes time to time. The layout may change, or the url may change. It will make the crawler fail or need to rework from time to time. So it is better to use API if there is any. Here is an example from Wikipedia API documentation:
import requests
revision_id = '764138197'
url = 'https://en.wikipedia.org/w/rest.php/v1/revision/' + revision_id + '/bare'
headers = {'User-Agent': 'MediaWiki REST API docs examples/0.1 (https://www.mediawiki.org/wiki/API_talk:REST_API)'}
response = requests.get(url, headers=headers)
data = response.json()
print(data)
Use Regex to bend the knee
Sometimes the data is plain in the open but you can’t grab it because you do not know how to distinguish the html element. For example, you want to see all the species and their urls from Macaw wikipedia page, but there are lots of links you do need. Then, simply use regex to determine them:
import re
import requests
from bs4 import BeautifulSoup
response = requests.get("https://en.wikipedia.org/wiki/Macaw")
soup = BeautifulSoup(response.content)
print(soup.find_all('a', href = re.compile(r'.*macaw'))) # regex to get urls end with macaw
Look for API calls in using developer tool
Dynamic websites usually use API calls to get the content from the backend. You can look for these calls and use them to get data. Here is an example, if you go to the search bar on Wikipedia website, type something and open inspect element or any other developer tool. Then go to the network section and click on the XHR tab/checkbox, you should see the RESTful API calls it is making to get the data. Use the requests library to get them.
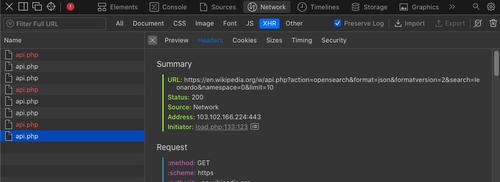
Here is a sample code to call the API:
import requests
url = "https://en.wikipedia.org/w/api.php?action=opensearch&format=json&formatversion=2&search=leonardo&namespace=0&limit=10"
print(requests.get(url).json())
Use map, filter functions
map, filter are extremely powerful functions in Python. Using them, you can drastically reduce codes and clean up your data. Suppose you want to get data from Django’s Wiki page, specifically you want to get version numbers from the releases table. The table looks like this:
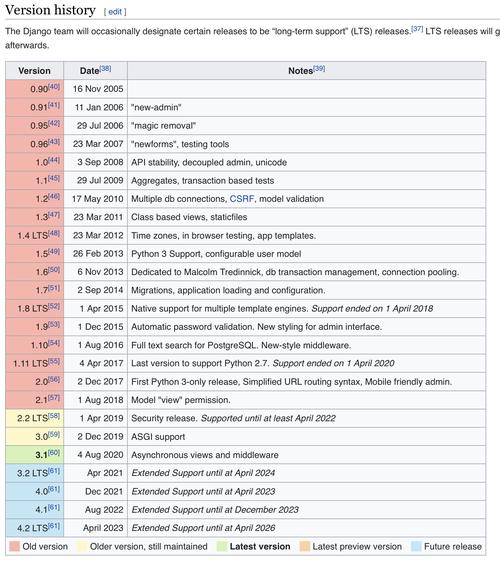
Let us get the table from that page:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Django_(web_framework)"
response = requests.get(url)
soap = BeautifulSoap(response.content)
table = soap.find('table', {'class': 'wikitable'})
Now we can fetch the values from table
values = table.find('tbody').find_all('tr')
But as you can see, all the values of the table are not versions. Let us use map function to get the versions only. We know that the first column of a row is the versions column, and we can get it via .find() function of bs4.
values = map(lambda x: x.find('td').find('span').value, values)
Now we have all the html elements from the version column. But we do not need data from the rows which do not contain any information. Time to clean it up via filter function:
values = filter(lambda x: x!= None and x.get('data-sort-value'), values)
We are almost ready, a final map function to get the value from each row and print it.
print(list(map(lambda x: x.get('data-sort-value'), values)))
A nice thing about using filter and map is that, they are generators; they do not hold up memory unless you execute it. Meaning until we called list() method, it was not taking any space at all.
If there is an excel or csv file, you are in luck
If somehow you get a hold of CSV or excel data from a website, then you are lucky. If it is a CSV, then simply csv library from python:
import csv
import requests
url = 'https://dumps.wikimedia.org/other/pagecounts-ez/wikistats/SquidDataVisitsPerCountryDaily.csv'
cr = csv.reader(requests.get(url).content.decode(), delimiter=',')
for row in cr:
print(row)
If you have excel file, then use xlrd:
import xlrd
url = "https://wiki.openoffice.org/w/images/f/ff/Sample_Spreadsheet_format_all.xls"
book = xlrd.open_workbook(file_content=requests.get(url).content)
print(book.sheet_names())
BTW, pandas provides excellent support for getting data from csv and excel files. Please checkout their documentation.
You can get data from PDF as well
You can scrape data from PDFs as well. You can use a library called pdftotext library which uses poppler to extract texts from PDF. But keep in mind that the data coming from PDFs are in plain text, it is really hard to identify what data you want to scrap. It is better to use regex to find data. For example:
import pdftotext
from io import BytesIO
import requests
url = "https://upload.wikimedia.org/wikipedia/commons/e/ef/Sample_Syllabus_for_Wikipedia_assignment.pdf"
response = requests.get(url)
pdf = pdftotext.PDF(BytesIO(response.content))
text = print("\n\n".join(pdf))
Mimic actions like login or form submission
You can easily mimic html form submission or actions like login using requests. Lets say, you want to submit a form on a certain website. First, use the inspect element/developer tool by browser to see what kind requests are made to the server. Probably it will be a POST request. Now see the payload, headers and url. Now use it in requests:
import requests
url = "https://example.com"
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
"User-Agent":"Mozilla/5.0"
}
payload = {
"username": "username",
"password": "password"
}
session = requests.Session()
resp = session.post(f"{url}/login", headers=headers, data=payload)
# Now you are logged in, let us get /profile page
resp.get(f"{url}/profile")
Need more robust solution, then use Scrapy
Some servers have mechanisms to prevent DDOS attacks or prevent multiple hits from a single IP. So it is better to not hit those websites in a limited interval. You can use Scrapy like solution which allows hitting from multiple IPs. They also provide ways to run multiple scrapping jobs and make the scraping process faster.
Selenium is the last resort
You should consider Selenium as a last resort. If you can’t crawl the website anyhow, then use Selenium. But probably you can’t scrap Facebook or Twitter like websites using it.
In conclusion
Scraping becomes necessary for collecting essential data which can be used on various purposes like Data Science. There are fantastic tools built using Python to help you with them. I hope this guideline will help you with getting started on scrapping. If you have any questions or opinions, please share in the comment section below. Cheers!!
Last updated: Jul 03, 2026

